I once had a complicated conversation with one of my customers in retail, about the information used to describe a customers. He explained to me that in his company, in a B2B context, one customers is identifiable by one name, one address and one legal code. Do you agree with him ? I don’t, and the source of this difference of opinion is the denormalization concept. It is a fundamental notion in data management, which is why I propose to explore it in this post.
How does data denormalization work?
Data normalization
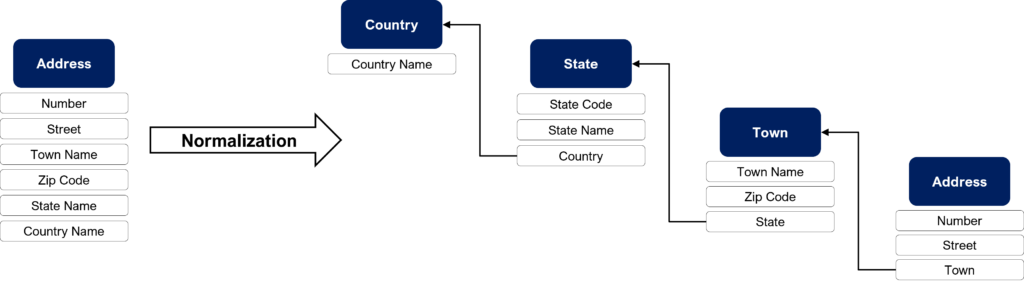
Normalization is the process of optimizing a logic model to make it non-redundant. This process leads to data fragmentation in multiple tables. For information, most of the time master data management projects consist of normalizing data. From a conceptual point of view, data normalization seems obvious but converting legacy data is a really huge investment.
The simplest example to explain this concept is the address case:

In this example, let’s first consider an address with its country, state, town, zip code, street and number: 1180 NE 201st Terrace, Miami, FL 33179, USA. Now we can basically compare it to a neighborhood address, which gives us:
- 1180 NE 201st Terrace, Miami, FL 33179, USA
- 1181 NE 200th Terrace, Miami, FL 33179, USA
It is obvious these two addresses share the same state, town, and zip code. Then, to normalize the previous model, we will simply add some objects to design a hierarchy:
Data denormalization
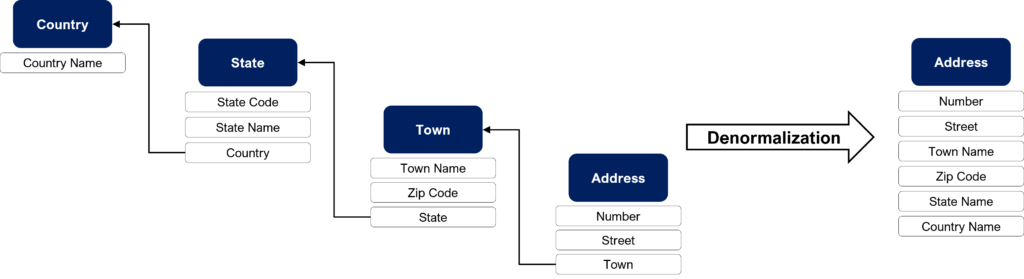
Data denormalization is a conception process consisting of grouping together several tables, that are linked by references, into a single table. This must be done consistently with the relationships between these tables. The objective of denormalization is to improve database performance when running searches on the tables involved, by implementing the joins rather than calculating them. For example, designing a star schema is a denormalization process.
In other words, denomalization is the opposite process of normalization:
What is the impact of data denormalization ?
Once we understand the denormalization concept, we might wonder about the impacts of this technique on the data. Denormalization should be used carefully because it involve normal form violation. In other words, it generates data structure defects and these defects generates data quality errors (sometimes false information). Here, you will find some examples of data architecture defects (it is just an overview). Remember that all models you will see are correct, but data consistency needs to be controlled with processes, business rules, and data flows.
Non atomic attributes
The simplest example to explain this case is the user name. We see here that:
- Tom Smith is understandable
- It is not possible to identify the first and last name for Ruby April
- It is technically not possible to tell if Charles is a first or a last name (this is a common French example)
- It is technically not possible to identify the first and last name for Jean Charles Dupond
| Case | Name |
|---|---|
| 1 | Tom Smith |
| 2 | Ruby April |
| 3 | Jean Charles |
| 4 | Jean Charles Dupond |
Another, more frequent example is the commentary field. It is regularly designed to allow users to record information they had not identified in the business requirement definition phase. Most of the time, due to lack of control, this results in a very low data quality which makes it unusable.
Indicator as an object attribute
This request is frequent in the customer domain (especially CRM or MDM). Sometimes, users ask for customer revenue in the creation form. it is generally not a good idea because if you do that, you will probably get the previous year’s revenue. Over the years, the resulting database will contain heterogeneous information.
Calculable information
The simplest example to explain this case is the age:
| ID | Name | First Name | Age |
|---|---|---|---|
| 1 | Smith | Tom | 34 |
| 2 | Johnson | John | 23 |
| 3 | Brown | Sonia | 29 |
With this table alone, it is impossible to tell if the age column is true because you don’t have the birth date or the recording year. Imagine Tom has been in the database for 10 years, he would be 44 today.
Redundant information
The customer in a B2B context is the best example to understand this type of data architecture defect. In Google Maps, if you for search Google in New York, the result will look like this:
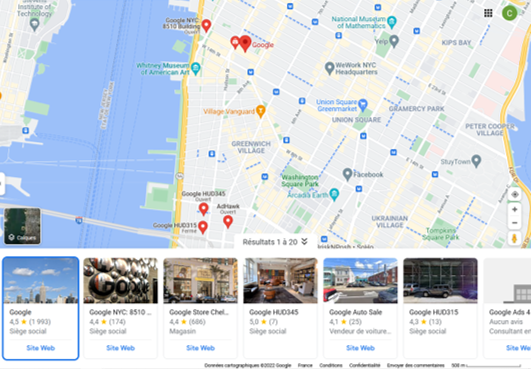
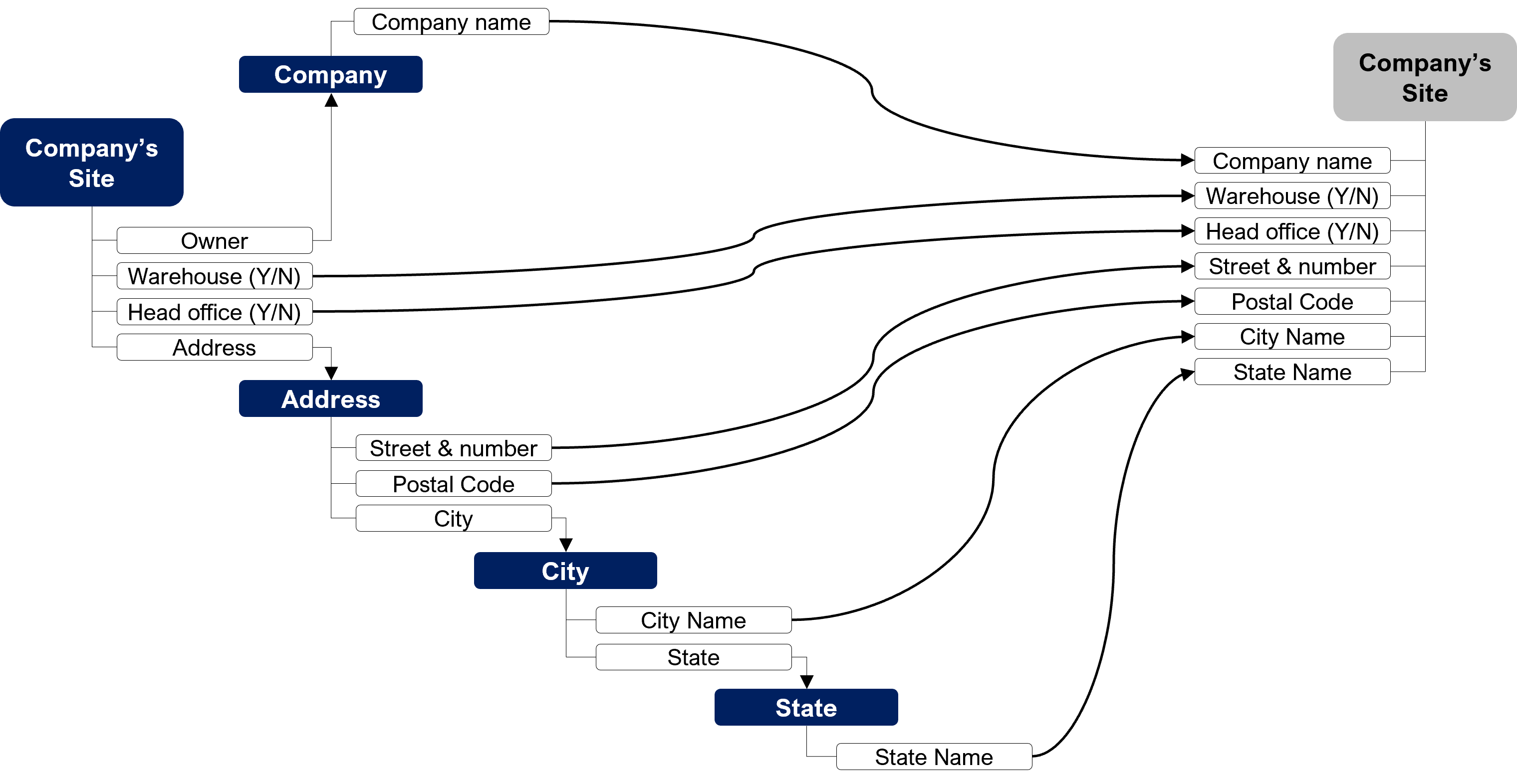
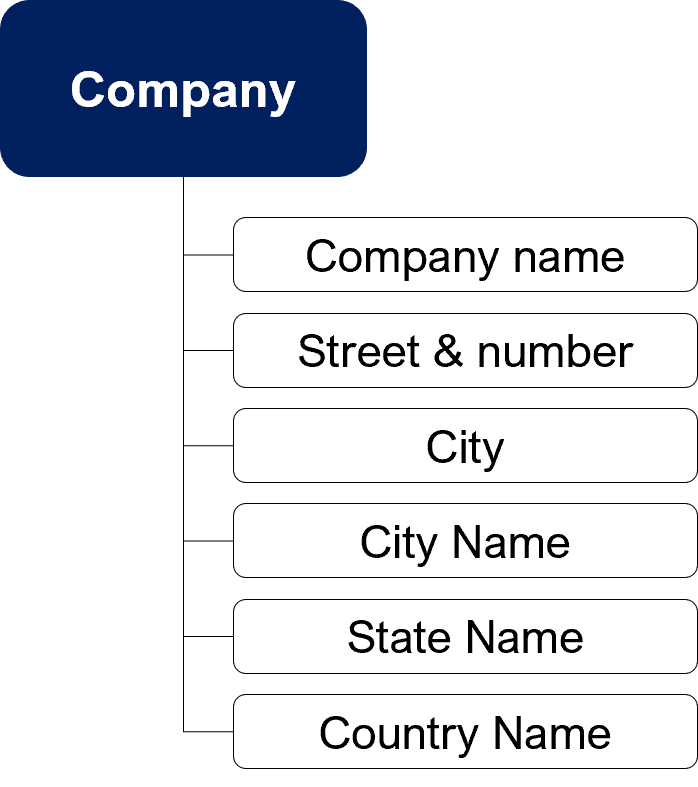
As you can see, a company can have multiple addresses. When you want to correctly design a company in a database, you should do it this way:
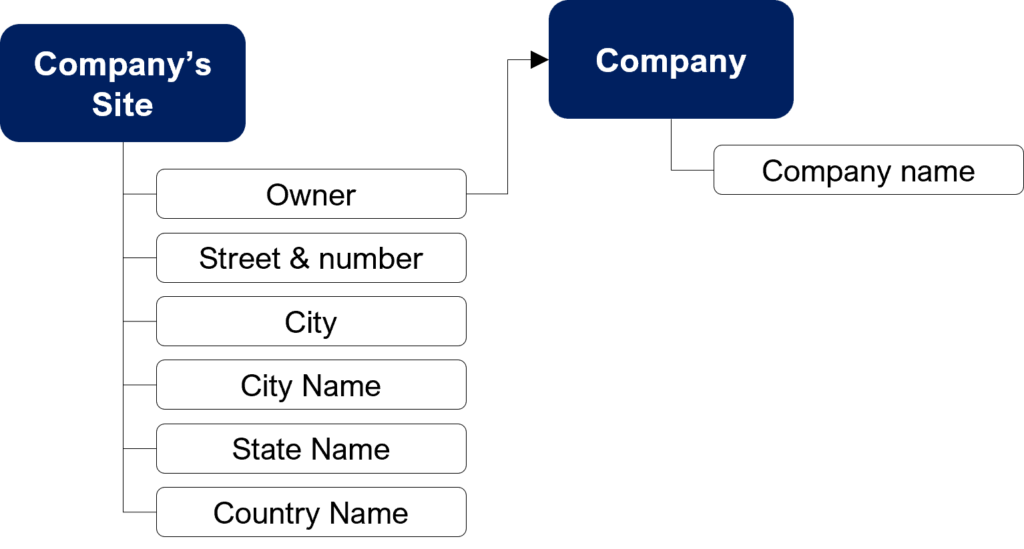
But most of the time, you will find it in its denormalized form in the source database. It is an issue because you cannot control exactness of the company name. As a consequence, you will probably not be able to consolidate data:
| Company Name | Street & Number | City | … |
|---|---|---|---|
| 85 10th Ave | New York | … | |
| 345 Hudson St | New York | … | |
| Gogle | 315 Hudson St | New York | … |


4 thoughts on “What Is Denormalization in Databases?”
Comments are closed.