
This is the second post in a series which compares the operational impact of the three major data warehouse design techniques. After the previous post that explored the star schema, this one explores a snowflake schema example. We will summarize the transport example and address a first comparison between star and snowflake schema.
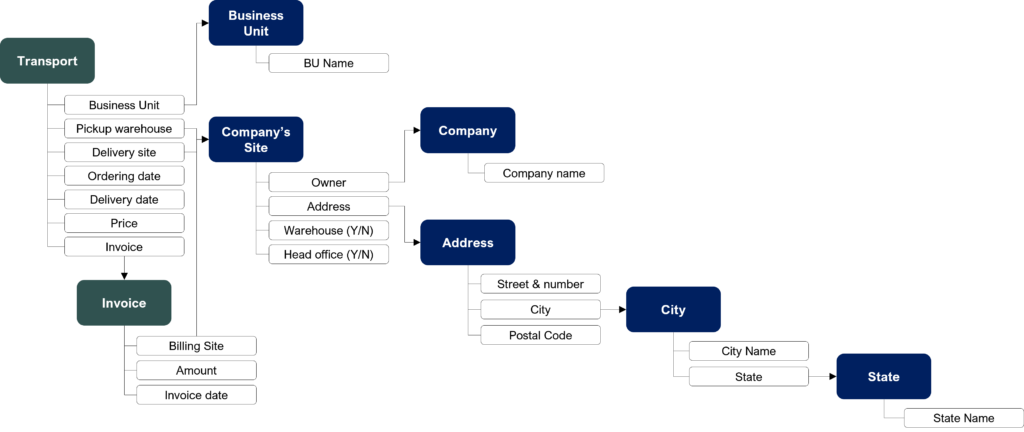
Transport example review
The main components in our example are the following:
- Master data:
- Geographical hierarchy: This hierarchy is composed of three levels, Addresses, cities, and states.
- Companies: This concept represents customers, we describe a company by its object and its sites. A company can have more than one site, that’s why we see a link from the site to the company.
- Business unit: This concept represents the transport company teams (be careful, it is the company that executes the transport, not customers teams)
- Transactional data:
- Firstly, the transport: This concept describes the transport and gives:
- The business unit that sells/ executes it
- The pickup and the delivery sites of the transport
- The ordering date and the delivery date
- Secondly, the invoice: We imagine that customers are billed each month, all transport executed in the month is part of the bill. This concept describes the invoice and gives:
- An amount which is the sum of transport prices for the customer this month
- The invoice creation date
- Firstly, the transport: This concept describes the transport and gives:
If you want more details on this example, this post contains a step by step description.
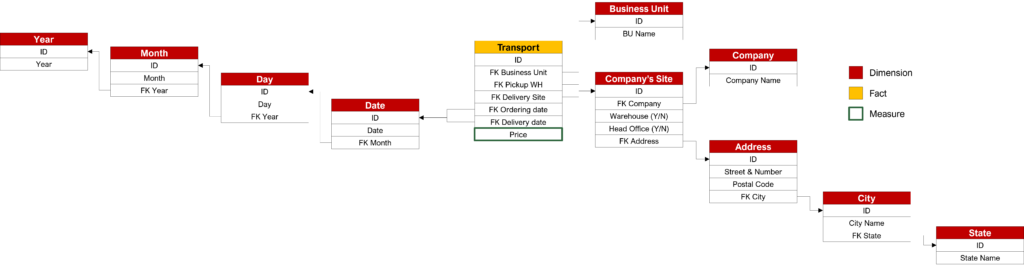
Corresponding snowflake schema
When you build a snowflake schema, you will have to choose between purism and pragmatism. Actually, the snowflake schema corresponds to our conceptual data model except for the time dimension. As a purist, we can design our snowflake schema example as follows:
The result is complex and the question that arises is: what is the added value compared to the star schema? The following table gives the pros and cons of each approach. We will explore each item in detail afterward to further explain the star and snowflake schema comparison.
| Item | Star Schema | Snowflake |
|---|---|---|
| Information redundancy | ||
| Usage complexity | ||
| Usage performance | ||
| Data loading performance | ||
| Modeling capabilities | ||
| Disk space usage |
Star and snowflake schema comparison
Information redundancy
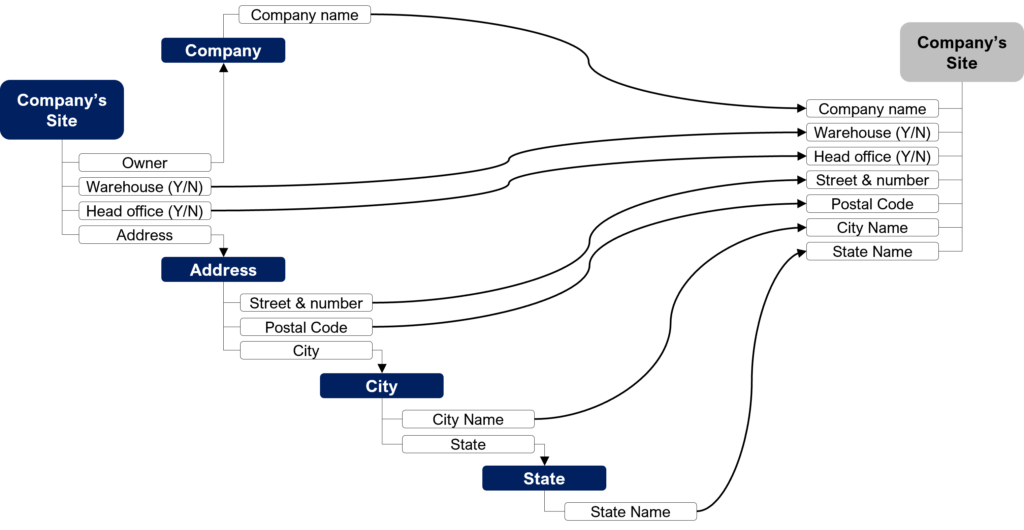
This is certainly the main drawback of the star schema: information gets duplicated. To understand it, let’s see how geographical data is stored in the two schema examples. As you can see, in the star schema, city name and state name are duplicated. This design increases the risk of errors in the data (especially in case of update).
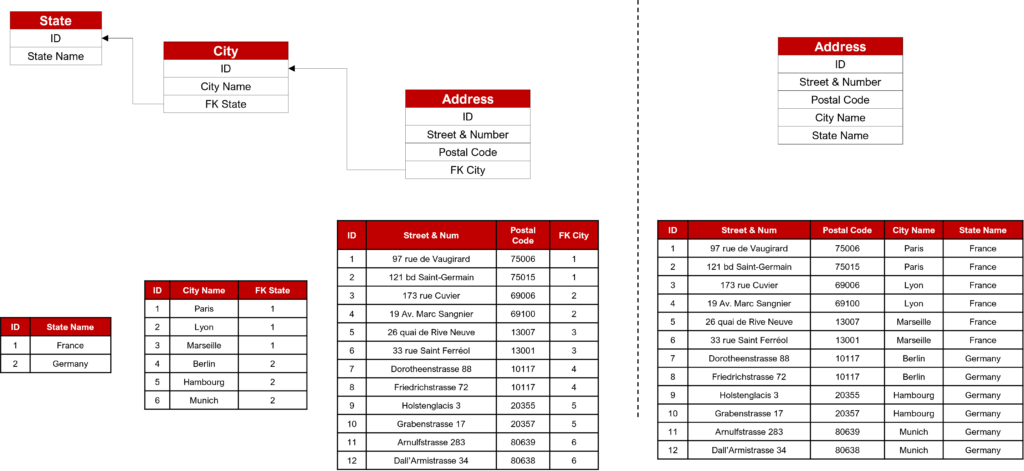
Usage complexity
The snowflake schema uses more joins between tables. Let’s compare the time dimension to understand that. As a result, in the snowflake schema, you will have to browse four levels to get data by year. The snowflake schema generates extra cost to get data.
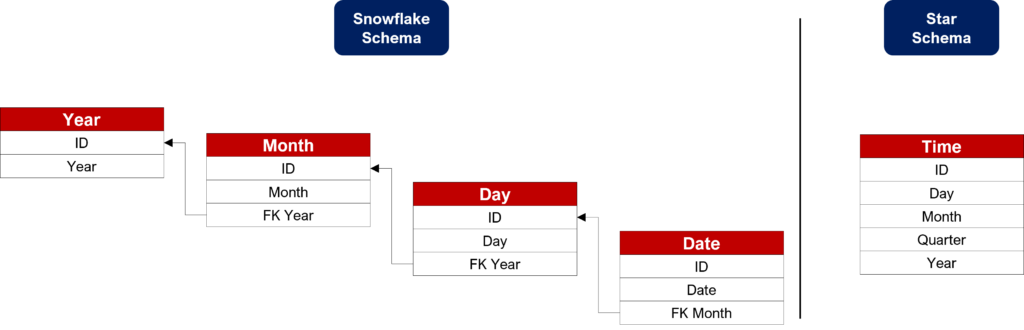
Usage performance
As explained in the usage complexity, the snowflake schema generates more joins between tables compared to the star schema. This fact generates performance issues too, especially during the cube generation step.
Data loading performance
As explained in the star schema example review, the star schema requires some data transformation to be generated. Since these transformations are executed in the ETL, its performance will be degraded. The snowflake schema requires fewer transformations.
Note : The transformations you see in the previous schema are typically executed by an ETL tool like Pentaho PDI or Talend data integration.
Modeling capabilities
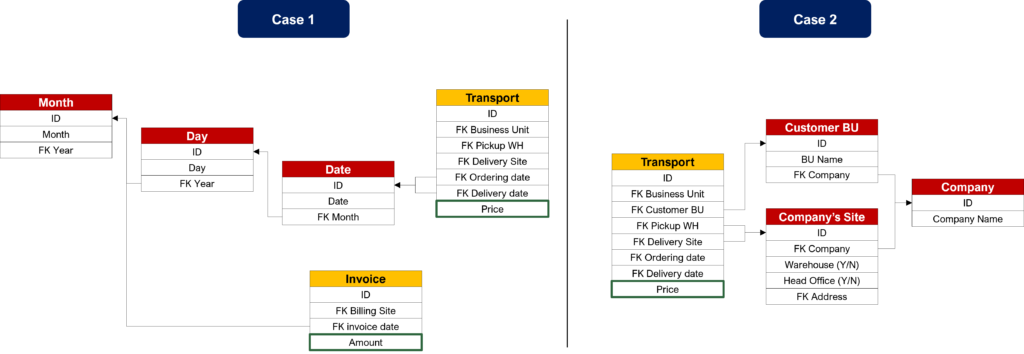
There are two cases where the star schema does not allow to design data: the fact comparison at multiple levels, and the parallel hierarchy. In our example, we can add a customer business unit and design the invoice to show that. Remember that an invoice is generated each month for a customer:
Disk space usage
Last point, the disk space. In the star schema, data gets duplicated. Therefore, it needs more disk space. This argument is regularly used to justify the snowflake schema but it has been admitted that we are talking of about 10 to 20 percent of the space.
